

De todos los medios tradicionales, el que más dificultades ha tenido para aprovechar las herramientas digitales de posicionamiento es la radio. Y es que el audio presenta retos especiales a la hora de competir por el posicionamiento. Google quiere cambiar esto con ayuda del machine learning.
El futuro de la radio, al igual que el de los otros medios tradicionales, está en peligro. Pero mientras el texto y el video han logrado afincarse gracias a plataformas como YouTube y los servicios de blogging, el audio presenta retos que todavía están por superarse. Por tal motivo, Google News Initiative, se unió a la emisora KQED y a KungFun.AI para mejorar las posibilidades de posicionamiento de las noticias en audio.
Recientemente hemos visto una nueva oleada de start-ups que buscan potenciar el audio como elemento básico de interacción entre las personas. Tal es el caso de Clubhouse, una red social que gira en torno a las conversaciones de audio en tiempo real. La cual, a pesar de estar limitada solo a los usuarios de iPhone y a un registro estrictamente por invitación, se convirtió en un unicornio. Adicionalmente, recientemente se pudo conocer que ya superó los 10 millones de usuarios registrados.

Pero el auge de la popularidads del audio en tiempo real trae nuevos retos. Por ejemplo, Google reconoció las dificultades para encontrar audio, partiendo de que primero hay que convertir el audio en texto para poder buscar o clasificar el contenido. Lo cual, desde el punto de vista de tendencias, pone al audio en desventaja para ser encontrado con rapidez y precisión. “La transcripción requiere tiempo, esfuerzo y ancho de banda de las redacciones, algo que no abunda hoy en día. Aunque se han producido grandes avances en la conversión de voz a texto, cuando se trata de noticias, el listón de la precisión es muy alto.” Afirmó Google
Por lo tanto, la transcripción requiere de una combinación de elementos que son difíciles de conseguir hoy en día. Y si bien se han producido grandes avances en las tecnologías de reconcimiento de voz, en los referente al audio en tiempo real (como las noticias), la precisión sigue estando lejos de los estándares ideales.
Google está utilizando IA para explorar el futuro del audio de las noticias
En una entrada reciente a su blog, Google reveló estar trabajando conjuntamente con KQED y KungFu.AI, para realizar pruebas para determinar cómo se pueden reducir los errores y el tiempo de publicación de las transcripciones de los audios de las noticias. Y en última instancia, hacer que el estas sean más fáciles de encontrar.
Para Google, la noticias publicadas solo en audio se “encuentran en un lugar similar al de los artículos de los periódicos en la década de 1990: difícil de encontrar y de clasificar por tema, fuente, relevancia o actualidad.”
Por un lado, KQED es la emisora de radio pública más escuchada de Estados Unidos y una de las mayores organizaciones de noticias de San Francisco. Por otro, KungFu.AI es un proveedor de servicios de IA y líder en Machine Learning aplicado.
El futuro de la radio tiene que superar el reto de identificar correctamente quién, qué y dónde
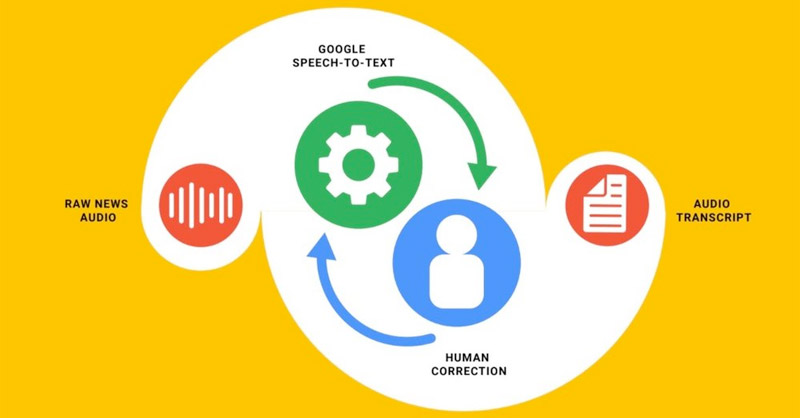
En las pruebas para comprobar la accesibilidad y el posicionamiento en las plataformas digitales, KQED y KUNGFU.AI, aplicaron las últimas herramientas de conversión de voz a texto a una colección de audio de noticias de la emisora.
Las noticias por regla general abordam las “cinco W” (inglés para: quién, qué, cuándo, dónde y por qué). Por desgracia, la IA suele carecer del contexto en el que se grabó el audio, como por ejemplo la identidad del orador o la ubicación de la noticia. Por lo tanto, estas pruebas demostraron que uno de los retos más difíciles de la conversión automática de voz a texto es identificar correctamente el conexto del audio transcrito.
Adicionalmente, en el caso del audio de las noticias locales de KQED es común encontrar referencias y términos relacionados con temas, personas, lugares y organizaciones contextualizadas en la zona de San Francisco. Los locutores utilizan expresiones locales, las cuales son más difíciles de identificar para la inteligencia artificial. Por lo tanto, cuando las herramientas de IA no entienden dichos términos autóctonos, los modelos de machine learning hacen su mejor estimación de lo que se dijo.
Por ejemplo, en la pruebas realizadas por Google, “The Asia Foundation” se transcribió incorrectamente como “age of Foundations”. De la misma manera, “misgendered” se transcribió incorrectamente como “Miss Gendered”.
Algo más que un error de transcripción
Los resultados de las pruebas ejemplica el reto para ganar relevancia al que se enfrenta el audio en tiempo real. Y que para los creadores de contenido, no se trata sólo de errores de transcripción, sino de problemas que cambian el significado de un tema. Lo cual puede causar vergüenza a un medio de comunicación.
Entonces, para mantener la precisión se debe recurrir a un personal humano para corregir manualmente las transcripciones. Lo que es es costoso de hacer para cada segmento de audio.
Ahora mismo, confiesa Google, el modelo de machine learning no aprende de sus errores. Apenas se está empezando a probar un sistema de retroalimentación en el que las redacciones podrían identificar los errores comunes de transcripción. De modo que sea posible enseñar para el mejoramiento del modelo de aprendizaje automático.
La lucha por el posicionamiento
A decir verdad, Google apenas está arañando la superficie de un problema de años. El cual empezó a cobrar relevanco últimamente, como consecuencia del empuje que ha tenido el audio en tiempo real. La realidad es que sin transcripciones, los motores de búsqueda no pueden encontrar estas historias, lo que limita la cantidad de audios de noticias y conversaciones relevantes que la gente puede encontrar en línea.
Es decir, el video y el texto cuentan con plataformas y herramientas que los ayudan a posicionarse de forma relevante. Pero en el caso del audio, todavía hay un largo camino por recorrer antes de que puedan competir por una posición destacada en temas en tendencia.
Google: Confiamos en que, en un futuro cercano, las mejoras en estos modelos de conversión de voz a texto ayudarán a transcribir el audio en texto más rápidamente, lo que, en última instancia, ayudará a la gente a encontrar las noticias de audio de forma más eficaz.
